Buenas Prácticas y Evaluación
En esta unidad discutiremos dos etapas del proceso de visualización que no hemos mencionado hasta ahora: buenas prácticas a la hora de diseñar, y evaluación del trabajo realizado. Primero veremos un listado de buenas prácticas, ideas y guías que suelen llevarnos por el camino correcto. Ahora bien, las buenas prácticas se ejercen en el diseño y desarrollo de una visualización. En resumen, las prácticas que comentaremos son las siguientes:
- Función antes que forma: no pongas la carreta por delante de los bueyes.
- No todo necesita ser coloreado: un uso adecuado y acotado de colores puede resaltar un mensaje.
- Un Buen Paradigma de Interacción: la estructura vista general
->zoom y filtrado->vista detallada es un punto de partida seguro para nuestros proyectos. - Es mejor Ver que Recordar.
- Considera que toda historia se cuenta desde una Perspectiva: no existen los datos duros y tampoco la visualización objetiva.
- Distorsiones y Bases
!=0: cuidado con visualizaciones que mienten (sea intencional o no). - No usar 3D sin tener una justificación.
- No usar 2D sin tener una justificación.
Éstas prácticas no son reglas que no se puedan romper, pero tenerlas en consideración nos permitirá diseñar mejores visualizaciones; podemos romperlas si nos preguntamos antes por qué las estamos rompiendo, de modo que tengamos claro el beneficio de hacerlo. Recordemos que la efectividad de una visualización depende no solamente de la codificación visual, sino también del contexto de quién realice la tarea.
Hay otra etapa importante que sucede después del diseño, del desarrollo, y de la puesta en marcha: la evaluación que nos permitirá saber si nuestro trabajo cumplió con los objetivos planteados, es decir, si resolvió las tareas para las que estaba diseñado. Es lo que veremos al final de esta unidad.
Función antes que Forma #
Hemos visto en el curso el proceso de diseño de una visualización como datos -> tareas -> codificación visual. El viejo dicho “función antes de forma” se refiere a que antes de tener la forma (la codificación visual) debemos tener clara la función (la tarea). En un proyecto es mejor enfocarse en la funcionalidad que provee la solución a un problema, antes que pensar en cómo se va a resolver. Como diseñaremos visualizaciones para otras personas, debemos tener claro lo que necesitan, no lo que quieren, como lo muestra este clásico cómic utilizado en administración de proyectos:

La primera imagen representa lo que pide el cliente, un columpio muy complejo e inusable, la última lo que realmente necesitaba, un columpio sencillo con una rueda. Un ejemplo real y familiar sucede cuando alguien pide a su unidad de Data Science un “dashboard” — eso es lo que quiere, pero no necesariamente lo que necesita. Esto implica que necesitamos comunicarnos constantemente con la contraparte que utilizará la visualización para lograr entender la tarea a realizar.
No todo necesita ser coloreado #
Prácticamente siempre acudimos al color como un canal para expresar atributos. Sin embargo, no siempre es adecuado utilizar los colores con todas las marcas que dispongamos. Veamos el siguiente ejemplo de line_chart, donde cada línea representa la evolución de tasa de fertilidad de un país:

Por mostrarlo todo terminando viendo nada. Una visualización más efectiva se enfoca en las marcas que son relevantes para la tarea que se desea resolver. Por ejemplo, si la tarea es comparar algunos países específicos con el resto y mostrar la tendencia mundial, se pueden utilizar colores para destacar los países relevantes, agregar una línea que muestre el promedio mundial, y dejar en el fondo con un color gris el resto de los países:

¿Cómo luciría esta idea con datos actuales? El siguiente gráfico muestra las defunciones en la Región Metropolitana de Chile en los últimos años:

Este gráfico cuenta una historia terrible de manera efectiva. ¿Cómo se vería con cada año utilizando un color distinto? Debido a la diferencia en la cifra de personas fallecidas, posiblemente podríamos realizar la tarea de cuantificar la diferencia y la evolución de ésta, aunque con distractores que nos harían menos eficientes.
Entonces, no solamente debemos elegir una paleta de colores que sea accesible y efectiva, también debemos decidir cuánto colorear. Otra consideración que debemos tener es que en ocasiones (cada vez menos) nuestra visualización será impresa en blanco y negro, y por tanto, nuestra elección de colores debiese ser compatible con ese escenario.
Un Buen Paradigma de Interacción #
Quizás una de las problemáticas que tenemos a la hora de enfrentar un proyecto es como estructurarlo. Si ya tenemos los datos y las tareas definidas, ¿cómo definimos la profundidad de la visualización?¿Cuál es el orden de las visualizaciones, de las interacciones?
Existe un paradigma influyente en visualización llamado Visual Information Seeking Mantra (“el mantra de la búsqueda visual de información”) propuesto por Ben Shneiderman. Consiste en la siguiente secuencia de acciones para sumergirse en los datos y operar con ellos:
Vista global primero
->filtrar y hacer zoom->detalles a medida que se necesiten(en inglés: overview first, zoom and filter, then details-on-demand).
La vista general permite identificar patrones globales, comparar, resumir; procedemos a una vista donde los datos se visualizan con más detalle, pero con un criterio que los ha filtrado. En un sistema interactivo, esto permite decidir dónde fijarse, qué llama la atención, dónde puede ser necesario profundizar. En una infografía, esto puede determinar qué mostramos primero y cómo componemos en una página las siguientes visualizaciones. Finalmente, la vista detallada permite saber más del ítem específico de los datos que nos interesa. Entre la vista general y la detallada puede haber varios niveles.
En general las visualizaciones que aplican este paradigma son complejas, con múltiples capas de interactividad. Existe un tipo de técnica llamada focus+context que ejemplifica parte de este paradigma interactivo, en la que una visualización tiene al menos dos partes: una donde se muestra a grosso modo el dataset (context), y una donde se muestra con mucho detalle el contenido de la parte de interés (focus). Estas técnicas suelen ser interactivas no solamente en términos de hacer clic, sino en reaccionar a lo que hace la persona que utiliza el sistema. Un ejemplo es la visualización Periphery Plots, donde el contexto lo da una línea temporal (que puede tener visualizaciones auxiliares o no) y el detalle contiene series temporales para cada atributo del dataset, cuya extensión se puede modificar a gusto tanto desde el contexto como desde cada una de las visualizaciones detalladas:
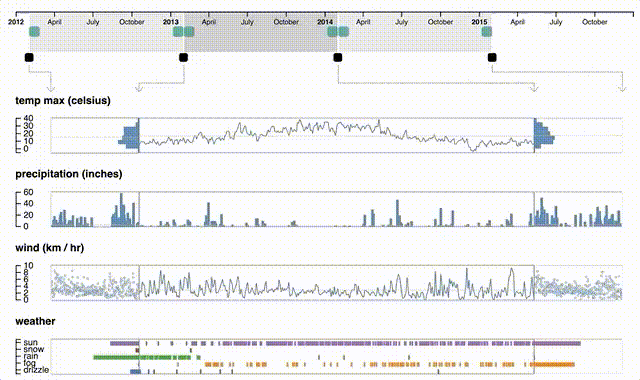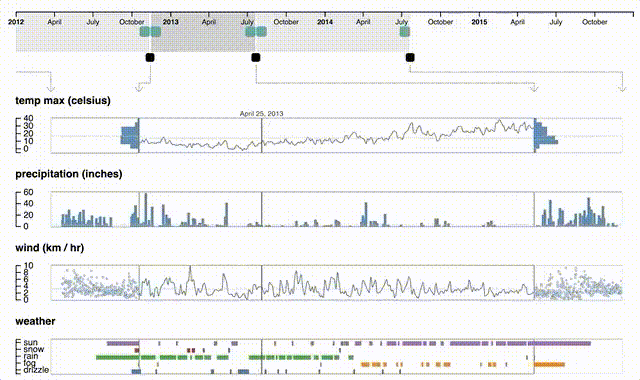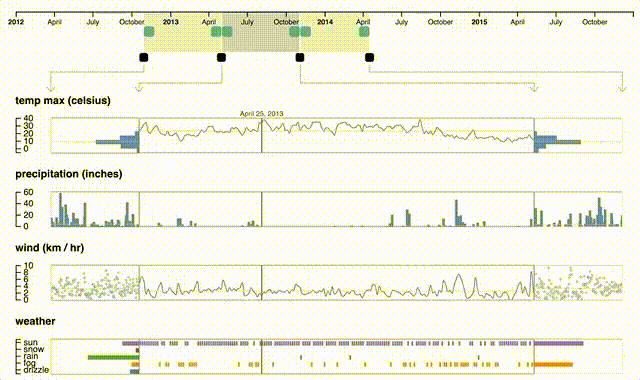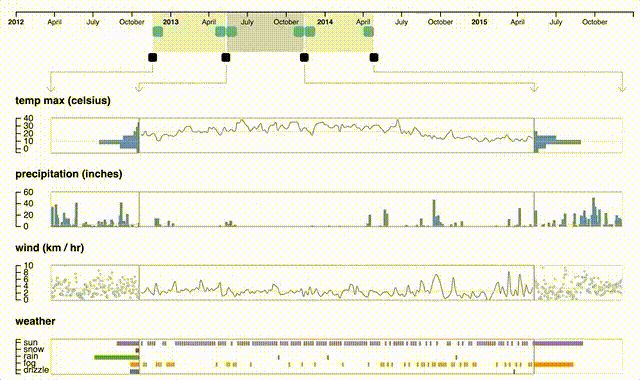
El paradigma plantea desafíos, particularmente cuando los datos son grandes: ¿cómo se define una visión global? Una solución es mostrar distintas vistas locales, semi-agregadas. ¿Cómo se traslada este paradigma a interfaces en dispositivos móviles, donde el espacio para una vista global es limitado?
Es mejor Ver que Recordar #
Cuando tenemos múltiples datos que queremos comparar, tenemos alternativas como utilizar distintos gráficos para cada dataset, hacer uso de la animación e interactividad, o desplegar un gráfico sobre el otro. Las dos primeras opciones suelen ser necesarias cuando los datos son complejos, en caso contrario, la tercera opción puede ser factible.
Cuando utilizamos distintos gráficos, si éstos están cerca, es fácil comparar elementos desplazando nuestro foco de atención entre vistas paralelas. En cambio cuando utilizamos interactividad o animación, nos daremos cuenta que es difícil comparar elementos si solamente veo uno y tengo que recordar el otro. Aunque una animación es buena para mostrar la transición entre un dataset y otro, si hay demasiadas transiciones, cada una con varios cambios, es preferible utilizar small multiples, es decir, múltiples visualizaciones pequeñas pero que comparten la codificación visual de modo que podamos comparar entre ellas. Una manera de hacerlo usar la memoria es destacar visualmente la diferencia relevante para el análisis. Este ejemplo de Martin Krzywinski nos da una guía visual de cómo hacerlo:

Tal como dice el gráfico, tenemos que ayudar a quien utiliza la visualización a ver lo necesario en ella para llevar a cabo la tarea.
Considera que toda historia se cuenta desde una Perspectiva #
Se dice que los datos son duros y que son objetivos, pero esta visión de los datos es simplista y errónea. Por un lado, los datos son capturados por un sistema diseñado con un propósito específico, y por definición no abarcan todo lo posible — son una visión parcial del fenómeno que estemos estudiando. Es más, cuando hacemos visualización, las elecciones que realizamos a la hora de elegir variables y atributos, de definir títulos y nombres, de elegir colores y disposiciones en la pantalla, y otras, están sujetas a nuestra propia retórica. Lo que elegimos incluir en una visualización es tan importante como lo que decidimos excluir de ella.
Nick Diakopoulos explica el siguiente caso publicado en el New York Times:

Esta visualización de tipo heatmap permitía a las personas que leen el periódico posicionar su opinión respecto al gasto público e los Estados Unidos entre dos ejes: reducir gasto o no hacerlo, incrementar impuestos o no hacerlo. Sin embargo, la opción de incrementar gasto no está disponible, así como la de reducir impuestos. No es lo mismo decir no reducir gasto que incrementar gasto, y ciertamente la posición en el eje y variará en función de como sea etiquetado ese eje en el heatmap.
El sitio The Correspondent realizó una exploración visual sobre cómo la codificación visual y otros elementos gráficos en los mapas cambian la percepción sobre la inmigración irregular en Europa. El primer mapa, que es el más frecuente, utiliza colores rojos (culturalmente asociados al peligro), flechas (que pueden dar sensación de invasión, pues es lo utilizado en mapas de guerra) y un título que habla de “inmigrantes ilegales”:

Una versión neutral de este mapa utiliza el término “inmigración irregular” (que es correcto, puesto que las personas no son ilegales), elimina el uso de flechas, pues indica el lugar por el que llegan las personas a Europa, no la dirección, y utiliza un color azul que no es asociado al peligro:

Ambos mapas muestran la misma información pero son percibidos de manera distinta. Sin embargo, siguen omitiendo algo: no sabemos cuál es la proporción de personas que migran en Europa. Los números nos parecen grandes, pero, ¿lo son realmente? El siguiente esquema muestra que la inmigración irregular es pequeña en comparación al total de inmigración en el continente, de hecho, es mucho menor al total de personas que emigran desde Europa:

La exploración de The Correspondent también considera alternativas a no utilizar un mapa. No siempre es necesario utilizar uno cuando hay información geográfica.
Por tanto, la retórica detrás de una visualización es importante, ya que influirá en como nuestra visualización es comprendida (sea esto lo que se busca de manera consciente o no). Ahora bien, estos sesgos a la hora de mostrar los datos no siempre son evidentes para quienes diseñan las visualizaciones. Desarrollar la capacidad de dar un paso al costado y ver nuestro trabajo de manera externa no es fácil, pero es necesario.
Distorsiones y Bases != 0 #
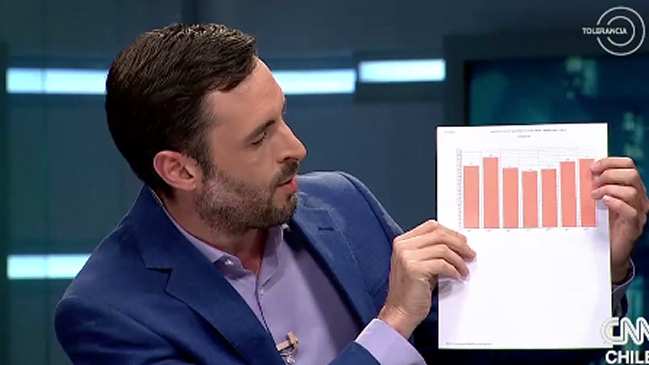
En el debate de las últimas elecciones presidenciales de Chile, el entonces candidato y actual presidente Sebastián Piñera enseñó el siguiente bar_chart de la victimización del país en tres años distintos:

El gráfico está hecho de manera que distorsiona los datos. Por un lado, la base de las barras no comienza de 0. Como en un bar_chart utilizamos el canal de largo de cada barra para realizar comparaciones, necesitamos que el largo (altura) de éstas sea representativo de los datos que presentan. En este caso, una barra cuyo valor es de 22.8 pareciera ser menor a la mitad de otra cuyo valor es 27.3. Lo primero que vemos son las barras, no los números. Como comenta Alberto Cairo en su libro How Charts Lie, incluso cuando están los números presentes tendemos a estimar erróneamente los valores que vemos en este gráfico. Por otro lado, el gráfico no contiene todos los años posibles, lo que permitiría ver la evolución de la victimización cada año. Un gráfico sin distorsiones sería como el propuesto por Daniel Matamala:
Quizás una mejora que se puede hacer en este último gráfico es utilizar el canal de color para expresar el período presidencial correspondiente.
Es por ello que un bar_chart debiese tener su base en 0. No hacerlo es distorsionar la percepción, por tanto, engañar.
La situación es diferente cuando hablamos de line_chart, donde no siempre es necesario tener la base del eje y en 0, puesto que la tarea no es comparar largos sino comparar posiciones y tendencias. El siguiente gráfico de positividad de exámenes PCR presentado por el ministro de salud Enrique Paris causó polémica:

Se criticó al ministro por no comenzar el gráfico con base en 0, sin embargo, no es necesario dada la tarea a resolver: medir la tendencia en el cambio de positividad. Ahora bien, eso no implica que el gráfico no distorsione los datos, puesto que si se mostrase toda la serie temporal de positividad de exámenes PCR, entonces se vería que es cierto que la tendencia había bajado en los últimos días, pero que su nivel seguía siendo excesivamente alto en comparación al inicio de la crisis sanitaria. El siguiente gráfico (que lamentablemente no incluye las fechas en el eje x) muestra la serie completa, ilustrando la distorsión que presenta el gráfico original:

Por un lado, el gráfico muestra que se omitió una parte sustancial de los datos, parte que influye en la interpretación de los resultados. También incluye una serie extra que indica que la positividad representada en el gráfico original es suavizada, puesto que representa el promedio móvil de esa variable.
Entonces, ¿cuál es la base adecuada para un line_chart? La respuesta está en la tarea a resolver. Por ejemplo, si existe un umbral de positividad aceptable (dado el contexto), es importante incluir ese umbral en el gráfico y destacarlo. El tamaño de nuestra visualización también influirá, por ejemplo, una visualización delgada y alta acentuará las tendencias en un line_chart, mientras que una visualización más ancha que alta las puede suavizar. Encontrar el balance dependerá del contexto en el que nos encontremos. ¡Esto implica que también la elección del valor máximo en el eje y puede alterar la percepción!
Recomiendo leer el libro How Charts Lie de Alberto Cairo para ver muchos ejemplos de estas situaciones de distorsión. La siguiente es una guía de casos comunes de distorsión extraída del libro:

La visualización es poderosa. Usémosla bien — evitemos distorsiones y fomentemos un análisis adecuado y riguroso de los datos para apoyar la toma de decisiones basada en evidencia.
No usar 3D sin tener una justificación #
Las visualizaciones en 3D pueden ser atractivas pero el peligro de cometer errores con ellas es alto debido a las siguientes características:
- La profundidad altera nuestra percepción del plano cartesiano.
- La oclusión de los objetos oculta información.
- La distorsión por la perspectiva provoca pérdida de información.
- El texto pierde legibilidad.
De acuerdo a los estudios de percepción, la profundidad no es un buen canal para codificar información. Aprendimos que la información en un plano tiene una mejor codificación: se corresponde 1 a 1 en la variación de la información, y contiene los canales más eficientes a la hora de trabajar con datos de magnitud. Aunque creamos que por ver y vivir en 3D una visualización sería mejor, la verdad es que no vemos en 3D, sino que en 2.5D, porque solamente vemos las superficies proyectadas en nuestro campo de visión:

En comparación, en profundidad debemos desplazarnos, en caso de ser una visualización interactiva. El movimiento de la cámara (o del cuerpo) es lento e introduce cambios en la escena que podrían pasar desapercibidos. En un plano podemos mover los ojos rápidamente y así adquirir información, sin cambios de cámara que oculten información.
El siguiente tema en el uso de 3D es la oclusión: los objetos más cercanos a la cámara pueden tapar a los que están más lejos. Este fenómeno oculta información, como se ve a continuación:

La oclusión se puede disminuir utilizando técnicas complejas de interacción, sin embargo, el problema persiste porque solo estamos atacando el síntoma, no la enfermedad: la oclusión es inherente a esta codificación visual.
El uso de perspectiva en 3D también provoca pérdidas de información, ya que interfiere con los canales que utilizan el tamaño para codificar atributos. En el siguiente ejemplo se visualizan documentos en un espacio 3D:

Los documentos que están más lejos pueden ser igual de importantes que los que están más cerca, sin embargo, al estar posicionados más lejos de la cámara podemos ignorarlos o bien asumir que no son relevantes. Podemos ejemplificar éste y otros de los conceptos vistos hasta ahora en una escena clásica de Jurassic Park, en la que se navegaba por un sistema de archivos en 3D:

Era una interfaz atractiva, y yo (niño en esa época), un par de años después cuando tuve un 486, quise explorar mi computador de la misma manera. En efecto es una manera entretenida, pero si la vemos con ojo crítico nos damos cuenta que encontrar información en esa interfaz es difícil: se nos oculta gran parte del disco, no vemos los nombres de las carpetas, el movimiento es torpe. Noten que la visualización no incluye el nombre de las carpetas de manera prominente. El texto en interfaces 3D es menos legible que en 2D debido a cambios en el tamaño debido a la profundidad, perspectiva y rotación. Además también hay problemas de rendering debido a la resolución. En 3D el texto se ve peor que en un plano 2D.
En resumen, los puntos anteriores nos indican que para datos abstractos se necesita una buena justificación para usar 3D. No es lo mismo una visualización de datos espaciales que de datos abstractos para los que no tenemos una referencia. Así, se pierde el poder de utilizar un plano para visualizar.
Veamos un ejemplo concreto de cómo convertir una visualización 3D sin justificación a una 2D efectiva. En este ejemplo disponemos de una serie temporal de consumo eléctrico en un edificio por cada día del año. La tarea a realizar es identificar perfiles (patrones) de consumo eléctrico, tanto en su forma como en las fechas en que se encuentra dicho perfil. La visualización 3D directa luce así:

La visualización en 3D permite mostrar todos los días del año en un solo gráfico. Sin embargo, el volumen de cada día hace que la comparación entre períodos de tiempo sea prácticamente imposible debido a la oclusión y a la perspectiva.
Para crear una visualización efectiva, el equipo transformó los datos y luego utilizó visualización en 2D. Primero, determinaron que en el dominio del problema (electricidad) era relevante definir patrones de consumo eléctrico. Para identificar estos patrones agruparon las series temporales con una técnica de clustering. De este modo, cada día pertenecía a un cluster específico, es decir, tenía un patrón único.
Luego visualizaron esos patrones, que también son series temporales, superimpuestos en un line_chart. La distribución de los patrones se visualizó en una visualización calendar_view (vista de calendario 2D). La visualización final luce así:

Como ven, es posible conocer los perfiles de uso energético y su distribución durante el año.
Veamos ahora un ejemplo de 3D justificado. Cuando la tarea es estudiar la forma en tres dimensiones, los beneficios de usar 3D superan los costos en la eficiencia de la visualización. No siempre es fácil, porque visualizar en 3D puede incluir visualizar volúmenes. El siguiente ejemplo muestra como la visualización 3D directa no es útil, pero una visualización 3D con geometría derivada, en este caso, líneas de contorno que caracterizan el volumen que junto con la interacción permiten apreciar la forma de lo visualizado:

Entonces, el uso de 3D es legítimo para datos que son 3D y que requieren manipulación y comprensión de las formas 3D.
No usar 2D sin tener una justificación #
Gran parte de las visualizaciones que hagamos serán 2D y está bien, utilizaremos los canales adecuados. Sin embargo, si nos enfocamos en la visualización de redes, es necesario que pensemos si necesitamos una organización en 2D de los nodos, o si podremos elegir una representación alternativa. Esto es crucial si leer texto es importante para la tarea a ejecutar.
Debido a como funcionan los algoritmos de organización de redes (como force_directed_placement), la densidad de la red puede dificultar la lectura de las etiquetas de cada nodo.
Si la tarea es principalmente topológica, entonces el uso de 2D para la red está justificado: los costos son menores a los beneficios. Pero de todos modos debemos tener cuidado con la legibilidad, aunque dependerá de la cantidad de nodos que tenga la red si esto será un problema. Un ejemplo de cómo visualizar una red de manera efectiva considerando texto es el sistema Cerebral:

En Cerebral se mezclan dos vistas distintas de la red, una de small multiples (sin texto) y otra vista detallada (con texto). La organización de los nodos es la misma en cada vista, lo que permite comparar distintas configuraciones de la misma red. Aunque lo parece, la red no se visualiza con un force_directed_placement, sino con un algoritmo que permite guiar la organización de acuerdo a la estructura de los datos (el contexto biológico). Hay muchas decisiones de diseño detrás de un sistema así, aunque no lo parece. Por eso, incluso al usar 2D, es importante pensar en qué justifica la codificación visual que utilizaremos.
Evaluar: Validar la Efectividad de Un Sistema #
El último tema de esta unidad es la evaluación, que busca validar la efectividad de un sistema de visualización. Entonces, lo primero que nos preguntamos es: ¿Qué significa que un sistema esté validado? Las respuestas son múltiples:
- ¿En términos de software engineering ? Que el sistema funcione adecuadamente, que no presente bugs.
- ¿En términos de las tareas a realizar? Que el sistema permita realizar las tareas de manera efectiva (resultados correctos).
- ¿En términos de desempeño? Que el sistema permita realizar las tareas de manera eficiente en el uso de recursos (menor tiempo posible, menor uso de memoria, etc.).
La única manera de saber si diseñados bien nuestro sistema es realizando una evaluación que responda ésas y otras preguntas. Hay herramientas formales para ello, provenientes de áreas como User Research, Interacción Humana-Computador, y otras. No es un proceso simple, puesto que cada persona interpreta una visualización de manera diferente y cada sistema puede tener hardware distinto. Sin embargo, en esta unidad no ahondaremos en las técnicas para realizar evaluación, sino en los qué y por qué de un proceso de ese tipo.
La investigadora Tamara Munzner propone un modelo anidado de visualización definido a continuación:

¿A qué se refiere con anidado? A que la evaluación no es un proceso que se realiza solamente al finalizar la implementación del sistema, sino que está presente de manera continua al entender el dominio del problema a resolver y al ejecutar cada etapa del proceso de diseño (datos -> tareas -> codificación visual) e implementación. Es crítico utilizar un enfoque anidado porque las etapas del proceso que no sean evaluadas pueden generar resultados incorrectos que crean errores de arrastre: si entendimos mal el problema porque no conocemos el dominio, entonces todo lo que hagamos después será inefectivo. Aunque entendamos el problema, si nuestros datos no son abstraídos y verificados de manera adecuada, las tareas generarán resultados incorrectos. Si las tareas están correctamente definidas, pero la codificación visual no cumple con los principios de efectividad y coherencia, la interpretación de las personas que utilicen la visualización puede ser equivocada. Si realizamos bien todo el proceso, pero el sistema implementado funciona mal (se cae, tiene bugs, etc.) o tiene mal desempeño (requiere más memoria de la que dispone el hardware, toma demasiado tiempo en hacer cálculos y no se puede interactuar, etc.), entonces no será adoptado y por tanto el sistema habrá fracasado en su propósito.
Al avanzar a través de estas capas debemos estar constantemente evaluando si lo estamos haciendo bien. De otro modo los errores se propagarán y no lo sabremos hasta que sea demasiado tarde, porque no será evidente su presencia hasta el final del proyecto.
Conclusiones #
En esta unidad tuvimos una vista general de algunas buenas prácticas a la hora de diseñar una visualización, y de la estructura anidada de un proceso constante de evaluación. Si consideramos estos contenidos a la hora de trabajar en visualización aumentaremos las posibilidades de que nuestro trabajo sea correcto. También las de que tenga impacto en el dominio donde trabajemos, de otro modo, nuestro proyecto corre el riesgo de generar resultados erróneos, o de no ser adoptado, de ser un árbol que cayó en un bosque sin que nadie lo escuchara.
Lecturas Recomendadas #
- Pautas de Alineamiento (Guidelines) para visualización en reportes del Urban Institute.
- Shneiderman, B. (1996, September). The eyes have it: A task by data type taxonomy for information visualizations. In Proceedings 1996 IEEE symposium on visual languages (pp. 336-343). IEEE.
- Carpendale, M. S. T., Carpendale, T., Cowperthwaite, D. J., & Fracchia, F. D. (1996, October). Distortion viewing techniques for 3-dimensional data. In Proceedings of the 1996 IEEE Symposium on Information Visualization (INFOVIS'96)(p. 46). IEEE Computer Society.
- Munzner, T. (2009). A nested model for visualization design and validation. IEEE transactions on visualization and computer graphics, 15(6), 921-928.
- Segel, Edward, and Jeffrey Heer. Narrative visualization: Telling stories with data. IEEE transactions on visualization and computer graphics 16, no. 6 (2010).
- Hullman, Jessica, and Nick Diakopoulos. Visualization rhetoric: Framing effects in narrative visualization. IEEE transactions on visualization and computer graphics, 17, no. 12 (2011).
- Lam, H., Bertini, E., Isenberg, P., Plaisant, C., & Carpendale, S. (2011). Empirical studies in information visualization: Seven scenarios. IEEE transactions on visualization and computer graphics, 18(9), 1520-1536.