¿Qué es Visualización?
Tamara Munzner provee la siguiente definición para Visualización de Información:
Los sistemas computacionales de visualización proveen representaciones visuales de conjuntos de datos diseñadas para ayudar a las personas a efectuar tareas de manera más efectiva.
No es la única definición, pero es la que mejor se adecúa a los propósitos de este curso, ya que está vinculada a data science: queremos resolver tareas (de un dominio específico) en sistemas computacionales.
Para motivar esta definición hay dos videos que podrían ser de interés. El primero se titula “200 países, 200 años, 4 minutos - La alegría de las Estadísticas” de Hans Rosling:
Es una maravilla ver en tan solo cuatro minutos una explicación visual del desarrollo de la humanidad en los últimos siglos. Esa misma historia se puede contar solo con palabras, pero, ¿sería igual de efectiva? Ciertamente no. Por otro lado, la cantidad de datos que fueron analizados no se pueden plasmar (al menos de manera realista) en palabras. Por otro lado, no podemos dejar de lado el carisma de Hans Rosling al contar la historia. En visualización también importa la comunicación.
El siguiente video es de la empresa Carto, que provee servicios de análisis y visualización de datos geográficos:
Un aspecto interesante del video es que no solo habla de las posibilidades de la visualización interactiva y geográfica, sino que también habla de la relevancia que tendrá la programación en el futuro profesional de las personas.
Ahora bien, los dos ejemplos que hemos visto utilizan el tiempo y la interactividad como recurso. Pero también es posible hacer visualización de impacto mundial con un gráfico estadístico. Un ejemplo de ello son las visualizaciones que ha publicado John Burn-Murdoch sobre la evolución del COVID-19:

Todas estas visualizaciones han sido realizadas con sistemas computacionales y ayudan a las personas a efectuar tareas de manera más efectiva. Veamos ahora los distintos aspectos de la definición de qué es visualización.
Las Personas son importantes #
Hay personas involucradas en todo el proceso de visualización, por tanto, la visualización no es un proceso automatizado. Algunos motivos de por qué es así:
- No siempre conocemos las preguntas que queremos hacer a los datos. En cambio, podemos explorarlos y crear la pregunta a través de la visualización.
- No podemos programar un algoritmo, o usar aprendizaje de máquinas, para responder cada pregunta.
- Porque algunos casos de uso no pueden ser automatizados, al no poder formalizar lo que se busca, pero sí poder reconocerlo al visualizarlo.
Además, las visualizaciones son utilizadas por una persona, y esta persona no suele ser quien programa, diseña o implementa la visualización. Un proceso de análisis, diseño y uso de una visualización luce así:

Los datos son filtrados y procesados, convirtiéndolos en información. La codificación visual genera una representación gráfica, que es percibida e interpretada por la persona que usa la visualización. Ahora bien, el contexto cultural y social es muy importante y define los esquemas notacionales de las personas. No hay dos personas iguales, por tanto, en visualización debemos considerar las características de quien diseña y también de quien usa el sistema. Hacerlo nos acercará a nuestro objetivo de efectuar tareas de manera más efectiva.
Enfoque en Tecnología y Computadoras #
Nuestra definición habla de sistema computacional. Históricamente, la visualización ha sido definida como una tecnología. Alberto Cairo dice en su libro The Functional Art:
La visualización debe entenderse como una tecnología[…] ¿Qué define a una tecnología?
- Es una extensión de nosotros.
- Es un medio para alcanzar un objetivo.
Un gráfico en sí mismo también es una tecnología, un medio para alcanzar un fin, un dispositivo cuyo propósito es ayudar a una audiencia a completas tareas específicas.
De hecho, se ha hecho visualización utilizando tecnologías analógicas. Si retrocedemos un poco, podemos ver el proceso completo de las visualizaciones que se incluían en The Economist en los 80s, consistentes en apilar y pintar transparencias:
Podemos retroceder más y llegar a los 20s, y encontrar el trabajo mecánico de Jacques Bertin en la visualización de matrices:

El diseño de Bertin era una maravilla no solo por su flexibilidad, sino también por el uso compartido que habilitaba. Hace algunos años en la conferencia IEEE VIS se le hizo un homenaje que reconstruyó sus mecanismos de visualización:

Los sistemas computacionales abren nuevas puertas en la colaboración. El enfoque más directo es la habilitación de un espacio de trabajo con datos, como los Wall Displays:

Un Wall Display no es solamente un monitor gigante compuesto por muchos monitores pequeños, también tiene nuevas maneras de interactuar con el sistema porque cada persona puede tener su propio puntero en la pantalla (o, en las implementaciones más avanzadas, tocar el lugar que desee). Pueden ver la historia detrás de esta imagen en el paper Adoption-Driven Data Science for Transportation Planning: Methodology, Case Study, and Lessons Learned.
Ahora bien, en este tiempo ya no es necesario que estemos todes en la misma sala para colaborar. ¡Las posibilidades que ofrece la Internet son vastas!
¿En qué otros aspectos las computadoras potencian la visualización? Sabemos que tienen una capacidad de procesamiento de datos que sobrepasa la capacidad humana con creces. Además, mientras más rápido se analicen los datos, no solo realizaremos tareas más rápido, sino que podremos realizar más. Podemos asegurarnos de explorar distintas fuentes de variabilidad en el proceso de análisis, distintos enfoques, etc. Y todo esto es escalable.
Quizás un límite que tienen las computadoras es el número de píxeles en pantalla. Sin embargo, también nos proveen interactividad. Una visualización estática permite una única vista de los datos, la interactividad permite que lo que se muestra cambie, creando potencialmente infinitas vistas de los datos. Una cita famosa en el área es la siguiente:
Una imagen vale mil palabras. Una interfaz de usuario vale mil imágenes.
– Ben Shneiderman
Un ejemplo típico de sistema interactivo son las dashboards. La siguiente fue construida con el software Tableau:

Como vemos, una dashboard tiende a contener múltiples visualizaciones entre sí, cada una respondiendo una pregunta específica, con todas las visualizaciones unidas en torno a un contexto común, en este caso una encuesta de movilidad en la Zona Metropolitana del Valle de México. Sin embargo el poder de la visualización emerge ante la interactividad: hacer clic en una visualización para obtener más detalles hace que todas las demás reaccionen y actualicen su contenido. Esto es útil cuando se ven patrones a nivel general y una persona quiere indagar en detalles por zonas o conjuntos de zonas específicas.
Lo Visual #
En este punto ya estamos convencidos del rol de las personas en la visualización. Otra pregunta que podemos hacernos es: ¿por qué enfocarnos en lo visual? ¿Por qué no “sonificación” o “representación táctil” de los datos?¿Por qué depender de la visión?
La visión es un sentido perceptualmente eficiente porque la comunicación con el cerebro es rápida y el procesamiento es paralelo a nivel preconciente. En contraste, otros sentidos son secuenciales (como el oído). Por lo demás, todavía no tenemos ni el entendimiento ni la tecnología para ser eficientes con otros sentidos, todavía no tenemos interfaces hápticas mainstream como las que hay en las películas (ej., Ready Player One).
Intenten encontrar el círculo rojo en la siguiente imagen:

La eficiencia con la cual pudieron responder la pregunta es una demostración de la percepción y del procesamiento en paralelo. Sin embargo, hay que considerar que no siempre la respuesta es tan fácil y rápida de obtener. Nuevamente, intenten encontrar el círculo rojo en la siguiente imagen:

Ahora tomó más tiempo, ¿no es así? Entender cómo funciona nuestra percepción es un área vigente de investigación, y visualización es parte de ella. Saber como percibimos permitirá crear interfaces y visualizaciones más eficientes.
Así, la visualización permite tener una representación externa de la información que reemplaza cognición por percepción. Pero, ¿qué es la percepción visual? El concepto ha sido de interés por siglos, no solo para las ciencias, sino también para el arte. De hecho, la explicación que más me gusta proviene del mundo del cómic, de la tinta de Scott McCloud:

Al ver una imagen recibimos información que es interpretada de manera automática (percepción), al leer un texto debemos utilizar nuestro conocimiento interpretarlo (cognición) y así poder percibir su contenido (percepción). Entonces, ¿dónde se ubica la visualización en este espectro? En el lado derecho, el análogo es ver una tabla con datos, que para nosotros es similar a leer un texto: hay que avanzar secuencialmente por la tabla de tal manera que capturamos e interpretamos secuencialmente su contenido, por ejemplo, para recordar el valor máximo o mínimo que contenga. Por el lado derecho, usualmente no existe una manera única de desplegar “una foto” de los datos. Por ello, una visualización, en cambio, provee una representación visual abstracta, ubicándose al medio del espectro.
Pero, ¿qué es la abstracción? Nuevamente usemos el ejemplo del cómic:

La abstracción es el mecanismo por el cual expresamos lo importante de una entidad. En el ejemplo, lo importante son los rasgos faciales que configuran la expresión de un rostro. Eso es lo que hace un artista. De manera equivalente, lo que hace un(a) diseñador(a) de visualizaciones es destacar los atributos importantes de los datos para que expresen información, y así podamos resolver tareas con ellos.
La metáfora del texto se puede ilustrar de la siguiente manera. La tabla contiene las ventas domésticas e internacionales de una empresa:

Algunas preguntas que podemos hacer sobre esta tabla son:
- ¿Cómo se compara el negocio de ventas domésticas en relación a las ventas internacionales?
- ¿Cuáles son los meses de mejor venta en comparación con sus meses vecinos?
- ¿Cual es el mes con peores ventas internacionales?
Responder cada una de estas preguntas implica tener que escanear los valores que contiene, memorizarlos, y realizar operaciones matemáticas en nuestra mente. Utilizamos la cognición. En cambio, una representación visual como la siguiente permite realizar operaciones que en la tabla son más difíciles. Comparar, buscar períodos relevantes, medir tendencias locales, etc.:
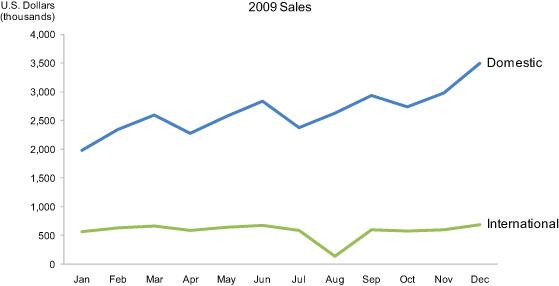
Para responder preguntas que no son directas (como máximos o mínimos) no necesitamos memorizar – nuestra percepción visual se encarga del trabajo. Por ello lo visual es tan potente.
Veamos otro ejemplo, un ejercicio clásico basado en la estadística descriptiva. De cierto modo, estas estadísticas ya abstraen los datos de una manera, al presentar medidas como el promedio, la varianza, la correlación, etc. Sin embargo, esta abstracción oculta variabilidad que puede ser importante, por un lado, puede inducir a errores de interpretación:
Hay dos panes. Usted se come dos. Yo ninguno. Consumo promedio: un pan por persona
– Nicanor Parra
Por otro lado, la estadística descriptiva limita la capacidad de encontrar algo que no esperábamos, porque la agregación usualmente se hace pensando en un fin específico. De manera análoga, puede ocultar patrones en los datos que sean relevantes.
Un dataset que ilustra estas limitantes se llama “El Cuarteto de Anscombe” y consiste en cuatro conjuntos con las mismas estadísticas descriptivas básicas: tienen el mismo promedio (x=9, y=7.5), varianza (x=11, y=4.125), correlación de r=0.816, y misma regresión lineal (y = 3 + 0.5x). Sin embargo, tienen naturalezas diferentes:

Vemos que datasets lineales, cuadráticos, y con outliers severos poseen las mismas estadísticas. Este ejemplo llevado al extremo (y al absurdo, de cierto modo) es el Datasaurus Dozen:

Todos esos datasets comparten las mismas estadísticas. Cuando les describan datos, siempre deben preocuparse de conocer su distribución. Lo meramente descriptivo puede ocultar información valiosa.
Por lo tanto, podemos decir que visualizar datos es abstraerlos de manera que podamos realizar tareas con ello. Lo siguiente que discutiremos es el enfoque en las tareas.
Tareas como Objetivo en la Visualización #
De acuerdo a la RAE, una tarea es un trabajo que debe hacerse en tiempo limitado. En nuestro contexto, lo que haremos es utilizar una tecnología (visualización) con el objetivo de lograr un resultado (realizar un trabajo) en un tiempo limitado. La búsqueda de un resultado diferencia a la visualización del arte visual. Una visualización puede llegar a ser arte, pero su propósito es proveer una herramienta efectiva para llevar a cabo una tarea, no ser una obra.
La definición de efectiva será importante en el curso. Depende del contexto: ¿cuál es la tarea que queremos lograr? En función de ello podremos decidir si más efectivo es:
- Más rápido: hacer algo en menos tiempo (en comparación con utilizar una visualización menos efectiva o no utilizar visualización).
- Más preciso: obtener un resultado cuantitativo más cercano a un valor exacto que utilizando otra técnica o sin utilizar visualización.
- Más barato: ¿nos cuesta menos recursos utilizar esta visualización para hacer la tarea? La definición de recurso es amplia. Puede ser dinero directamente, pero también uso de procesamiento, de memoria, etc.
- Más enriquecedor: ¿descubrimos algo que de otro modo hubiese pasado por alto?¿Generamos más valor?
Además es necesario considerar que no todas las tareas están relacionadas a necesidades de negocio. Hay ocasiones en que la tarea es única y personal, incluyendo actividades como explorar, aprender, divertirse, exponer.
Imaginemos que ya tenemos una noción de las tareas que debemos realizar en nuestro proyecto. La siguiente pregunta que nos debemos hacer es: ¿debemos usar visualización para cada una? ¡No siempre! Dependerá principalmente de dos factores: la claridad de la tarea y la disponibilidad de todos los datos necesarios para llevarla a cabo. Observemos el siguiente diagrama:

Entre los dos ejes mencionados hay tres situaciones:
- No hay suficientes datos estructurados. En tal caso, independiente de qué tan clara sea la tarea a realizar, no podemos visualizar los datos utilizando un sistema computacional, porque los datos no están dentro de dicho sistema.
- La tarea está claramente definida y todos los datos necesarios para llevarla a cabo están en el sistema computacional. En tal caso, probablemente podamos automatizar la realización de la tarea. No sería necesario usar visualización.
- Una situación intermedia: la tarea puede estar vagamente definida o muy clara, y puede haber datos estructurados en el sistema computacional, sin embargo, también son necesarios datos disponibles en las personas (por ej., su experiencia) para llevarla a cabo. Ésta es la situación ideal para usar visualización, ya que permite combinar el conocimiento humano con las capacidades computacionales, donde el todo es más que la suma que las partes.
Veamos dos ejemplos clásicos. El primero es el mapa de cólera en la Londres victoriana que hizo John Snow (el que sí sabe):

En el siglo 19, en plena epidemia de cólera, no estaba claro el modo de transmisión del cólera. John Snow proponía que se transmitía a través de las fecas, sobretodo en el agua, sin embargo, había otras teorías que tenían más apoyo, como la del miasma (es decir, que se transmite por “aire sucio”). El mapa muestra las muertes por cólera en el centro de la ciudad en 1854 y cómo se ubican cerca de las fuentes de agua, particularmente de la ubicada en la calle Broad. Entonces, podríamos decir que este mapa permite realizar la tarea de encontrar fenómenos relacionados con la incidencia de una enfermedad. Ahora bien, ¿se utilizó para ello? Este mapa considerado uno de los trabajos de visualización más influyentes, ya que se cuenta que John Snow detuvo la transmisión del cólera a través del mapa, y, al mismo tiempo, creó la epidemiología. Lamentablemente parte de esa historia épica es falsa, sin embargo, él sí utilizó el mapa en 1855 para evidenciar el modo de transmisión. Lo que sí sabemos, es que él estaba en lo correcto respecto a su teoría.
El segundo ejemplo también proviene del siglo 19, de 1857 en particular. La enfermera y estadística Florence Nightingale utilizó un gráfico de área polar (que lleva su nombre ahora, el diagrama de rosa de Nightingale) para medir la distribución de las causas de muerte en los hospitales en las colonias inglesas y entender su relación con los eventos importantes. El gráfico luce así (en su versión restaurada digital):

La composición de dos gráficos permite entender cómo se distribuyen distintas causas de muerte (codificadas en las áreas coloreadas en cada mes) antes y después de las intervenciones de higiene en los hospitales de la India. Por supuesto, su trabajo no se limita a este gráfico. Fue reconocida como la primera mujer de la Sociedad Real de Estadística en el Reino Unido.
En este curso veremos una manera de definir formalmente tareas para visualización. Ahora bien, no existe una manera única de identificar y categorizar las tareas. Por ejemplo, el Vocabulario Visual Interactivo del Financial Times define multiples tareas a realizar y para cada una lista las visualizaciones que pueden ser adecuadas para el caso. Su versión póster luce así:

Este tipo de taxonomía muestra que no todos los diseños de visualización son efectivos para cada tarea. Si estás leyendo esto, probablemente conoces o has realizado visualizaciones durante tu vida académica o profesional, y estás al tanto de algunos de esos diseños. Uno de los propósitos de este curso es expandir el espacio de soluciones conocidas, de modo que ante una tarea que se te presente en el futuro, puedas elegir entre las opciones que conozcan, que seguramente incluirán un diseño que sea al menos adecuado para realizar la tarea:

Nos queda una decisión aún. Si tenemos un conjunto de diseños/soluciones buena para una tarea, ¿cómo elegir? Dado que en visualización estamos abstrayendo datos, estamos decidiendo qué es importante de mostrar y cómo hacerlo. Recordemos, también, que tenemos que considerar a la persona que hará uso de la visualización. Teniendo todo eso en cuenta, podemos utilizar las siguientes dimensiones para elegir:

La elección de diseño no siempre se relaciona a cuál es la mejor visualización en términos objetivos, sino en los trade-offs involucrados. Las técnicas que son buenas en un contexto no lo son en otro. Por ejemplo, debemos elegir entre familiaridad y novedad del diseño. Si las personas objetivo son especialistas en visualización, quizás presentar una técnica novedosa sea buena idea, encontrarán la manera de interpretarla y navegarle. Pero si son expertos de otra área, o son el público general, como puede ser en el caso de un periódico, entonces debiésemos preferir una visualización que les sea familiar.
Siguientes pasos #
En este momento ya tenemos una imagen global de qué es visualización basados en una definición específica, una noción respecto a cuándo utilizarla y por qué, y conocimiento de sus beneficios en comparación con otras alternativas de abstracción. Por tanto, los siguientes pasos involucran conocer el proceso de diseño de una visualización, que se compone de tres etapas:
- Abstracción de los datos disponibles.
- Abstracción de las tareas a realizar.
- Codificación visual.
Esas tres etapas contienen la base teórica completa de este curso. Construiremos sobre ella las visualizaciones para distintos tipos de datos, y nos permitirán comparar entre visualizaciones y también evaluar si el diseño que nos entregan otras personas es adecuado.
Lecturas Recomendadas #
- Heer, Jeffrey, Michael Bostock, and Vadim Ogievetsky. A tour through the visualization zoo. Commun. Acm 53, no. 6 (2010).
- Van Wijk, Jarke J. The value of visualization. IEEE Visualization, 2005.
- Liu, Shixia, Weiwei Cui, Yingcai Wu, and Mengchen Liu. A survey on information visualization: recent advances and challenges. The Visual Computer 30, no. 12 (2014).