Cómo ser Data Scientist y NO morir en el intento — Parte 1
Trabajo como profesor investigador en el Instituto de Data Science de la Universidad del Desarrollo, y soy fellow de Telefónica Investigación y Desarrollo Chile. Hago clases (estamos dictando un Taller de Data Science), apoyo a estudiantes de doctorado y magíster en sus tesis, e investigo problemas de movilidad urbana desde una perspectiva colaborativa entre Data Science, Urbanismo e Ingeniería en Transporte.
.")
En mi tesis doctoral estudié distintas maneras en las que las personas se comportan de manera sesgada en la Web. He viajado presentando los resultados de mi trabajo, aprendiendo de los trabajos de los demás, y viendo como las mismas problemáticas tienen caras y expresiones diferentes en distintos lugares — y, algo que muchas veces se olvida: culturas diferentes requieren soluciones diferentes.
Utilizando esa experiencia como entrada, en este artículo quiero sintetizar lo que he aprendido en el camino para ser Data Scientist.
Introducción: El valor de los Datos
Hoy prácticamente nadie duda del valor de los datos, ni del potencial de la carrera conocida como “Data Scientist.” Como muestra, Harvard Business Review calificó esta carrera como “el trabajo más sexy del siglo 21.”

Personas de todas las edades y niveles de experiencia se preguntan cómo llegar a ese futuro, no solamente por lo auspiciosa que parece la carrera, sino porque se presenta de manera motivante, entretenida, y con potencial de cambiar la calidad de vida de las personas.
Pero llegar a ser Data Scientist es un camino que presenta desafíos intimidantes. Incluso alguien que pueda ser considerado genio(a) en un área específica, como computación, tiene altas probabilidades de fallar. Eso se debe a que se necesita una triada de habilidades para ser Data Scientist que no es fácil desarrollar, consistente en dominio matemático y estadístico, habilidades de comunicación, y pensamiento computacional.
Una triada que no se puede dominar repitiendo ejercicios o simplemente leyendo material. Wile E. Coyote y su incesante cacería del correcaminos es un gran ejemplo de ésto.

Ya sabemos como el Coyote, a pesar de ser un gran ingeniero, fallaba espectacularmente en cada episodio. Mi intención es que no les suceda lo mismo.
Un Poco de Historia
No es nuevo el uso de datos y su transformación en información útil para la toma de decisiones; es más, el registro y uso de datos no es algo propio de la era de la computación.

El primer censo en Chile se hizo el año 1813, y el de 1865, que aparece en la imagen, estimó las distribuciones de profesiones con respecto al sexo de las personas. Algo que todavía es de interés y que refleja la manera de vivir en la época. El de 1940 estudió la distribución de la población en base a la edad, de modo de realizar proyecciones que permitiesen saber cómo estaría configurada la población del futuro. Esto y más lo pueden ver en un libro del Instituto Nacional de Estadísticas con la historia de los censos en Chile.
Hay disciplinas que llevan siglos trabajando con datos. En esta sección quiero enfocarme en personas que rompieron los límites de sus respectivas disciplinas, ayer y hoy. Contaré cuatro historias, dos extranjeras y dos chilenas.
John Snow (for real) —Médico
Una de las historias más contadas en Data Science es la de John Snow, que sabía mucho y que en 1854 mapeó los casos de cólera en Londres a través de entrevistas, visitas a terreno, y revisión de registros. Al analizar el mapa postuló que la cólera se transmitía por el agua, debido a que la mayor cantidad de decesos estaban en casas cercanas a fuentes específicas. Esto, que hoy parece obvio, en ese tiempo era desconocido (de hecho, recién en 1885 se demostró científicamente la transmisión). La teoría prevalente de transmisión de enfermedades era la Miasma, o “aire sucio.”

John Snow propuso medidas que lograron detener la epidemia. Y su estudio dio inicio a lo que hoy conocemos como epidemiología.
Florence Nightingale — Estadística y Enfermera
Florence Nightingale, considerada pionera en el campo de visualización de información, estudió las causas de muerte de los soldados ingleses en la India, entre 1854 y 1856. En esos tiempos no existían medidas de higiene en los hospitales, y por supuesto, tampoco antibióticos. Como consecuencia, las tasas de mortalidad de soldados heridos eran altísimas.
Florence utilizó análisis estadístico y creó técnicas de visualización para realizar análisis. Concluyó que la higiene en los hospitales salvaba vidas. Algo que es obvio hoy, antes no lo era. Ella lo hizo evidente. ¿Cómo? Así:

No deja de ser sorprendente la calidad de ese diseño. Hecho hace más de 150 años.
Volvamos al presente.
Marcela Munizaga — Ingeniera en Transporte
Marcela Munizaga es docente en el departamento de Ingeniería Civil en Transporte de la Universidad de Chile, y hace casi una década utilizó los registros de las tarjetas bip! y los registros de GPS de los buses de Transantiago para inferir flujos de movilidad en la ciudad y entender cuáles paraderos funcionan, cuáles no, dónde es necesario uno, cuál es la velocidad de las calles, cuál es el beneficio de los corredores de buses, entre otras preguntas.
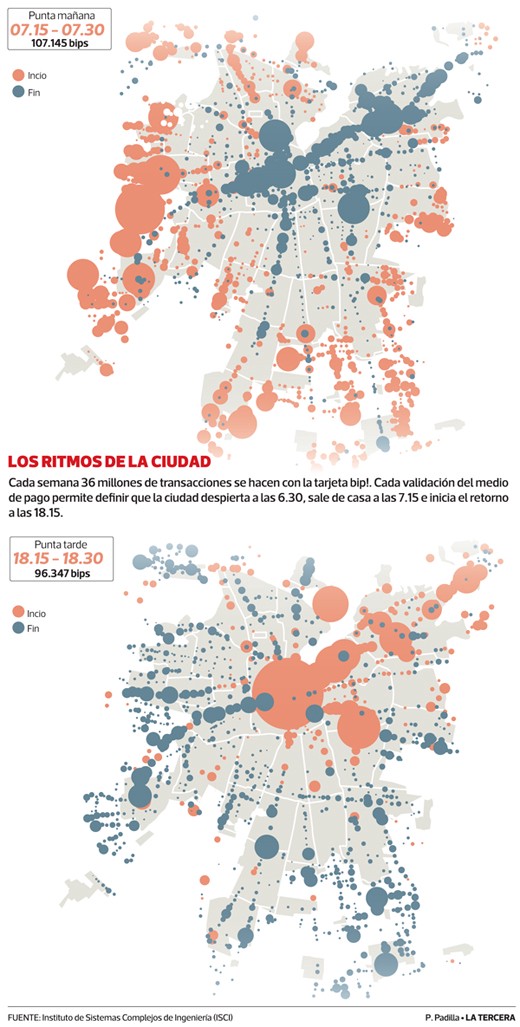
Su investigación no solamente produjo publicaciones científicas, sino que sus resultados están disponibles, año a año, en la página de la Dirección de Transporte Metropolitano. Estimar esta información a granularidades temporales finas (diarias, mensuales, anuales, etc.) es importante, puesto que la información actual que se utiliza para decisiones de transporte y movilidad se basa en encuestas. Encuestas que se hacen cada 10 años.
Sí, leyeron bien: cada 10 años.
Una ciudad como Santiago cambia más rápido que nuestra capacidad de hacer encuestas. Y, por supuesto, hay ciudades en Chile en las que estas encuestas nunca se han realizado. En esta página se pueden encontrar algunas, en formatos Microsoft Access (no es abierto, pero al menos lo publicaron).
Utilizando los registros de las tarjetas bip!, Marcela logró informar la toma de decisiones en planificación y gestión de transporte. Hoy, además de los registros de tarjetas, también utilizan la información de los GPS de los buses para estimar la congestión en las calles, entre otros problemas. Tecnología que no solamente se ha publicado como papers sino que también se ha transferido a entidades como la Dirección de Transporte Público Metropolitano (DTPM), a través de proyectos FONDEF. Quizás no lo vemos, quizás seguimos disconformes con el Transantiago, pero el sistema ha mejorado con el pasar de los años, y Marcela es una de las personas detrás de esa mejora.
César Hidalgo — Físico
La última historia que quiero mencionar es la de César Hidalgo. César es profesor en el Media Lab del MIT, donde dirige el grupo de Collective Learning (Aprendizaje Colectivo). De formación en física, César ha incursionado en diversas áreas utilizando un enfoque basado en datos, que podríamos llamar data-driven. Entre sus proyectos llaman la atención Pantheon, o los patrones que emergen de la historia desde un punto de vista global y cultural, con datos de Wikipedia; Immersion, o cómo nuestro correo electrónico permite reconstruir redes de comunicación y colaboración, y sus dinámicas a través del tiempo, con datos de GMail; y Place Pulse, el entendimiento de las ciudades a través de como percibimos visualmente las calles en imágenes de Google Street View.

El trabajo de César nos ha enseñado que el valor más importante hoy es la información, y que si queremos crecer como país, debemos abrazar la diversidad y el conocimiento. Entre sus actividades actuales, publicó el libro “El Triunfo de la Información,” viene constantemente a Chile a dictar charlas (la próxima será en el seminario VisDatos, en Enero), y participa en la formación de estudiantes en eventos como B4: Bits, Bots, Brain & Behavior.
https://www.youtube.com/watch?v=NEqF3XAd-yE
¿Qué tienen en común estas historias?
Aunque estas personas no son conocidas como data scientists, resolvieron problemas complejos que iban más allá de lo que sus propias disciplinas permitían ir, y, al hacerlo, mejoraron la calidad de vida de los demás. Hoy, eso es lo que hace un(a) Data Scientist.
La pregunta que emerge es: ¿cómo podemos definir esa nueva área de manera formal?¿Qué necesito para poder ser una persona que empuje los límites de su propia disciplina?
¿Qué es Data Science?
El artículo Data Science, Challenges and Directions de Lonbing Cao define Data Science como un área transdiciplinaria que unifica tres conceptos: los datos (data), el dominio (domain), y el pensamiento (thinking):

Las disciplinas involucradas son:
- Comunicación — se resuelven problemas concretos que, para poder ser identificados, es necesario escuchar a quienes tienen estas problemáticas, y también expresar los resultados del análisis y solución propuestos.
- Gestión — es necesario administrar múltiples fuentes de datos, sus significados, su disponibilidad; y también, gestionar las relaciones con múltiples stakeholders.
- Informática — necesitamos almacenar, consultar e interactuar con grandes cantidades de información.
- Estadísticas — modelaremos los datos y los resultados utilizando técnicas estadísticas apropiadas para el contexto.
- Computación — queremos computar algoritmos complejos, y necesitamos hacerlo de manera eficiente, incluyendo el uso de memoria, el uso de espacio, y el tiempo de cómputo.
- Sociología — el estudio de las relaciones entre personas u otras entidades es clave. En Data Science se trabaja con problemas de situaciones actuales, que afectan a personas e instituciones.
Aunque Data Science en Chile se imparte principalmente en las escuelas de ingeniería, particularmente en las que tienen Ingeniería en Computación, la computación y la informática son solamente una parte. Ése es justamente una de las debilidades del área en Chile, puesto que las escuelas de ingeniería no están entregando herramientas multidisciplinarias a sus estudiantes.
Complejidades
Las disciplinas mencionadas necesitan complementarse puesto que los problemas en cuestión no se pueden resolver utilizando solamente herramientas o modelos propios de cada disciplina. Los problemas que se pueden atacar con ciencia de datos son complejos por características como las siguientes:
- Los datos pueden ser de una escala que excede los límites de los métodos tradicionales, tanto a nivel de observaciones como de cantidad de features o dimensiones.
- Hay sesgos e imbalances en la información. Los métodos tradicionales tienen supuestos que usualmente no son respetados.
- Los datos pueden llegar en tiempo real, y su procesamiento puede ser difícil de realizar de manera eficiente.
- Los datos pertenecen a contextos distintos y provienen de múltiples fuentes.
- Los datos no están necesariamente estructurados ni tener distribuciones claras. Pueden estar incompletos y ser dispersos.
A estas problemáticas, que pueden ser consideradas de índole técnica o tecnológica, se suma que las relaciones o soluciones que estemos buscando pueden no surgir al utilizar técnicas tradicionales de asociación, correlación, dependencia, o análisis de causalidad.
En términos de comportamiento los problemas que están aquejando a nuestra sociedad involucran lo grupal, lo colectivo, y las granularidades espacio-temporales de los problemas son más finas de lo que pueden proveer las metodologías tradicionales.
Un ejemplo de esto es la movilidad dentro de la ciudad. En la Ingeniería en Transporte, una de las principales fuentes de información son las Encuestas de Viaje que mencioné al contar la historia de Marcela. Como toda encuesta, es cara de hacer y requiere un esfuerzo logístico enorme. Sin embargo, su resultado, aunque es muy rico, representa un “día promedio” de la ciudad.
Sabemos que ningún día es promedio. Las encuestas son como una foto de larga exposición donde la gente no se puede quedar quieta. Podemos apreciar cosas generales pero no los movimientos finos que nos ayudarían a analizar el comportamiento de las personas día a día.
Si la disciplina de transporte quiere resolver los problemas actuales y futuros, deberá colaborar con otras disciplinas para encontrar nuevas fuentes, y responder preguntas que actualmente no puede responder. Tendrá que diseñar nuevos métodos, o nuevos usos para métodos ya conocidos.
No considerar las complejidades mencionadas es peligroso. Por ejemplo, asumir que los datos no tienen sesgos puede traer consecuencias terribles para la vida de las personas. ¿Les parece exagerado? Imaginen que un sistema computacional debe decidir a quién poner en primer lugar en la lista de transplantes de corazón. Se suele pensar que si es computación, es algorítmico; si es algorítmico, no está sesgado.
Falso.
Vi una charla de Jeanna Matthews donde comentó que todos los días hay algoritmos que toman decisiones sobre nosotros. Primero, no sabemos quiénes son; segundo, no sabemos si la decisión es algorítmica; tercero, no sabemos si la decisión es justa o si considera características que consideramos privadas o desconocidas para los demas; y cuarto, no podemos exigir una explicación al respecto.
.")
Jeanna recomendó el libro Weapons of Math Destruction, que contiene historias como la siguiente:
A person who scores as ‘high risk’ is likely to be unemployed and to come from a neighborhood where many of his friends and family have had run-ins with the law. Thanks in part to the resulting high score on the evaluation, he gets a longer sentence, locking him away for more years in a prison where he’s surrounded by fellow criminals — which raises the likelihood that he’ll return to prison. He is finally released into the same poor neighborhood, this time with a criminal record, which makes it that much harder to find a job. If he commits another crime, the recidivism model can claim another success. But in fact the model itself contributes to a toxic cycle and helps to sustain it.
En resumen, un algoritmo de caja negra refuerza los sesgos en la sociedad, en vez de anularlos. Cuando entregamos cajas negras estamos obviando todos los sesgos que pueden tener los datos y las decisiones algorítmicas.
Por eso el resultado de un proceso de Data Science debe ser reproducible e interpretable. No solamente en términos de una recomendación de decisión, o una métrica específica. Es una caja que contiene herramientas, código, documentación, datos de entrada, datos auxiliares, resultados intermedios, e incluso resultados negativos. Lo que no funcionó también es valioso.
Esta caja debe contener múltiples piezas, de variados colores y formas. No es una caja negra.
El Proceso: ¿Cómo se construye esa caja de colores?
La siguiente imagen ilustra un proceso de Data Science:

Observamos que parte con un proceso de entrada (Input), donde existen datos, información, conocimiento, hipótesis, y en general, todo lo que necesitemos para poder iniciar la solución de una tarea analítica compleja.
El siguiente paso es la motivación, donde se redefinen las metas y tareas a resolver. Redefinir puede ser interpretado como refinar, acotar, redireccionar, o bien, moverse en una dirección opuesta. ¿Por qué sucede esto? Porque el problema que estamos abordando es complejo y no tenemos una visión clara de cuál podría ser la solución. Tenemos un punto de partida, una hipótesis, pero es común que las primeras hipótesis sean descartadas por ser ingenuas o insuficientes. El proceso es iterativo, puesto que en un comienzo no sabemos cuánto, cuándo ni dónde necesitaremos remotivar nuestro trabajo.
El tercer paso es la formalización de la hipótesis y la primera estimación de un resultado. Al definir una posible solución también debemos tener una expectativa de los potenciales resultados y de cómo llegar a ellos. Aquí podemos volver a la motivación si en nuestras primeras estimaciones nos damos cuenta que podemos mejorar la definición del problema a resolver. Este paso es crucial en la determinación de qué es Data Science, porque el proceso descrito no parece ser distinto de un proceso científico típico. Incluso, hay personas que argumentan que la ciencia siempre ha sido Data Science, porque el método científico se basa en datos para respaldar, documentar y medir la experimentación. Según ellas, Data Science es un buzzword y no algo nuevo.
Pero Data Science no es lo mismo que Science using Data. La ciencia en una disciplina usualmente no trabajaba con datos de otras disciplinas, ni resuelve problemas aplicados. Quizás un ejemplo de esto es la física, que genera conocimiento sobre las leyes que hacen funcionar el universo. Dicho conocimiento es extremadamente valioso, pero no siempre tiene una aplicación práctica o de corto plazo. Esa característica podría ser uno de los motivos por los que hay tantes físiques en Data Science ;)
La ciencia “a secas” prioriza la investigación básica, mientras que Data Science prioriza investigación aplicada, utilizando no solamente la pregunta de investigación como punto de partida, sino también la ingeniería y el diseño, y su aplicación a los datos. Es lo que plantea Ben Shneiderman en su libro The New ABCs of Research:
https://www.youtube.com/watch?v=bR3p7oHVn2Q
El cuarto paso es la de modelos y métodos, es decir, la generación de modelos formales, de la aplicación y creación de algoritmos, de la exploración de parámetros. Es en este punto donde usualmente veremos la necesidad de volver atrás para iterar nuevamente las etapas anteriores.
El siguiente paso es la evaluación y simulación. Aquí ejecutamos técnicas de evaluación de nuestros resultados, por ejemplo, mediante tests estadísticos, tests con usuarios, comparación con observaciones externas que consideramos ground truth o golden standard. Ahora bien, no siempre se puede evaluar completamente. Por ejemplo, en uno de nuestros proyectos actuales estamos estimando flujos de personas entre distintas zonas de la ciudad, y, sin embargo, los datos de la encuesta de movilidad solamente son representativos a nivel de comuna. Por ende, cualquier granularidad espacial más fina no tiene datos con los cuales compararse. Podríamos considerar fuentes externas, como los registros de tarjetas bip!, pero solamente consideran transporte público y contienen el sesgo de la evasión, o podríamos considerar los tags de las autopistas, pero esta información está protegida por las respectivas concesionarias y, de todos modos, está sesgado a quienes utilizan autopistas.
En cada una de las etapas anteriores estaba la posibilidad de volver para reiterar, refinar, mejorar, redireccionar. Cuando la solución cumpla con los criterios de aceptación, o bien con las restricciones del proceso, que pueden ser fechas, métricas de calidad, o simplemente aceptabilidad por parte de les stakeholders, entonces se ha producido conocimiento cuantitativo y accionable.
Como mencioné, la ciencia “a secas” no siempre genera conocimiento accionable en el corto plazo. Eso está bien — no lo genera porque no es su propósito. El propósito de la ciencia es avanzar el conocimiento y nuestro entendimiento de lo que nos rodea. El propósito de ciencia de datos es resolver problemáticas que mejoren la calidad de vida de las personas. Eso no descarta que un descubrimiento científico, que hoy puede parecer no aplicable, no sea crucial en el futuro.
Tendencias y Comparación Big Data y Business Intelligence
Otro argumento típico en contra de la existencia de Data Science es que es una nueva manera de decir Big Data, Business Intelligence, o Estadísticas.
En Google Trends podemos buscar las tendencias de búsqueda de trabajos de Data Science, Big Data y Business Intelligence.

Pareciera que el hype de Big Data ya tocó techo. Un gran amigo, que trabajaba en un centro de investigación en Barcelona, me contó de manera tragicómica que era común que llegasen empresas con bases de datos en Excel y les pidieran “que hicieran Big Data” a partir de esos datos.
A pesar del desconocimiento, Big Data sí puede tener cierta formalidad en su definición. Se basa primariamente en la escala. Podemos definir un algoritmo que funciona bien para 10, 100, 1000, un millón de elementos. ¿Y para un billón?¿Para varios terabytes de datos? Ya no parece tan sencillo.
Mi impresión es que el foco en Big Data no está en el proceso de análisis y descubrimiento de conocimiento, sino más bien en la tecnología necesaria para escalar el análisis. Gran parte de los resultados interesantes de Big Data en realidad utilizan técnicas sencillas pero cuya aplicación a cantidades enormes de datos (tan enormes que ni siquiera podemos imaginar en cuántos servidores están almacenados) requiere implementaciones especializadas.
.")
Por otro lado, hoy son muy pocas las compañías que realmente hacen Big Data, porque simplemente no tienen la cantidad de datos masivos que podría requerir estos esfuerzos. Google, Facebook, Telefónica, entre otras, son empresas que trabajan con millones de registros generados cada segundo. Y aún así no siempre se necesita Big Data. Por ejemplo, los datos que he usado en mis proyectos han sido analizados en servidores de alto performance, pero su cantidad está lejos de ser considerada “Big.”
Es por eso que hoy se habla de la importancia de Small Data. De hecho, es posible que Big Data como buzzword ya esté decayendo, frente a la formalidad y aplicabilidad de áreas como Data Science. Un ejemplo de que Big Data no siempre es aplicable es que puede ser cierto que los datos generados por sensores, tanto físicos como digitales (ej., la Web), no todo lo que contienen estos datos es valioso. Existe mucha información redundante y sin aplicabilidad.
El otro término que comparé es Business Intelligence. De cierto modo, en BI llevan décadas trabajando en problemas en base a datos, y por tanto sigue siendo un área relevante, pero va en caída. ¿Por qué? Porque sus procesos no son reproducibles, dependen de herramientas propietarias, y no están afectos a las complejidades que mencionamos anteriormente. Por ejemplo, en BI no se suelen incorporar datos de otras fuentes, los datos suelen estar estructurados (provenientes de sistemas CRM), y los resultados son decisiones de negocio. Es más, muchas veces se sabe que se puede obtener una respuesta a la problemática planteada, y la respuesta que se obtenga puede ser satisfactoria.
¿A qué me refiero cuando hablo de reproducibilidad? En Data Science podemos responder una problemática compleja para una ciudad, determinar las fuentes de datos complementarias y los parámetros necesarios para el modelo, y luego replicar el análisis en otra ciudad. Con ajustes, ciertamente, pero ya contábamos con una caja llena de herramientas, métodos, algoritmos, datos auxiliares, que nos apoyan. La caja de colores que habíamos mencionado anteriormente.
Otro aspecto importante que no se da en BI es que usualmente sus datos están limpios. Al provenir de procesos y sistemas de registro internos, es probale que los datos ya estén “masajeados.” En cambio, en Data Science, buena parte del proceso es la exploración, limpieza y filtrado de los datos.
No incluí Statistics en la búsqueda porque hay demasiados factores que alteran los resultados. Por ejemplo, los cientos de estudiantes en cursos de estadística en el mundo, buscando material para el curso. Sin embargo, estadística, como campo, es parte de Data Science. Una de las personas más influyentes en el ecosistema del lenguaje de programación R, Hadley Wickham, ha dicho lo siguiente:
The fact that data science exists as a field is a colossal failure of statistics. To me, that is what statistics is all about. It is gaining insight from data using modelling and visualization. Data munging and manipulation is hard and statistics has just said that’s not our domain.—Hadley Wickham
En mi opinión la separación va más allá de la limpieza y procesamiento de datos. La persona que hace estadísticas no está necesariamente adquiriendo el lenguaje del dominio en el cual está aplicando su solución, y no trabaja necesariamente en equipo. Un(a) Data Scientist no solamente resuelve el problema utilizando herramientas, también se involucra en la definición y evaluación de éste.
¿Quién es Data Scientist?
Entonces, ¿quién es Data Scientist? Las disciplinas mencionadas en la definición de Data Science son un punto de partida, y hoy, posiblemente quienes tengan formación estadística o de ciencias de la computación son quienes tienen una mejor base para comenzar.
Pero el aspecto profesional de una persona no es la disciplina que estudió sino la mezcla de sus habilidades que ha desarrollado a lo largo del tiempo.
Curiosamente, al igual que el gráfico que muestra las disciplinas que conforman Data Science, existe una gran cantidad de diagramas de Venn que se han utilizado para explicar las habilidades de un(a) Data Scientist. Una simple búsqueda en Google Images muestra lo siguiente:

De todas las visiones al respecto, hay dos que quiero destacar. Una que llamo cuantitativa y otra que llamo cualitativa.
La visión cuantitativa
Drew Conway propone el siguiente conjunto de habilidades de un(a) Data Scientist:

Veamos las habilidades mencionadas.
- Hacking Skills — es decir, la habilidad de hacer cosas programando, de crear herramientas, manipular datos, conectar sistemas. No estoy del todo de acuerdo con esta definición, yo prefiero directamente hablar de habilidades de pensamiento computacional. Ya aclararé este punto más adelante.
- Math & Stats — lo que hemos dicho. El modelamiento matemático y estadístico es necesario.
- Substantive Expertise — con esto se refiere a un dominio del área en la que se está aplicando Data Science.
Las intersecciones de las áreas son las siguientes:
- Maths & Stats + Substantive Expertise — investigación tradicional. Tenemos una pregunta de investigación sobre mi propia área y la respondemos utilizando herramientas cuantitativas.
- Maths & Stats + Hacking Skills — aprendizaje automático. Podemos hacer modelos que aprendan desde los datos y que podemos utilizar para predecir, inferir, entender, explorar.
- Hacking Skills + Substantive Expertise — lo que el autor llama “zona de peligro,” puesto que es una persona que tiene habilidades para hacer cosas, de expresarlas utilizando el lenguaje del área, pero sin entender realmente lo que está sucediendo. La llama “una persona que sabe lo suficiente para ser peligrosa.”
Llamo a esto una visión cuantitativa porque dice que un(a) Data Scientist se determina por las herramientas computacionales que le permiten resolver problemas de diversas áreas utilizando técnicas formales. Sin embargo, aquí queda fuera un factor importante: la comunicación.
La visión cualitativa
La pionera Hillary Mason propuso el siguiente gráfico para definir a un(a) Data Scientist:
. Cuando se lo mostré a mis estudiantes en la UDD y les pregunté por las referencias de películas tuve que recoger el carnet :(")
El gráfico se toma las cosas con humor. Ejemplifica las distintas intersecciones entre áreas como personajes de Jeff Goldblum en películas ochenteras y noventeras. Si dejamos el humor de lado, el diagrama es similar al anterior, pero reemplaza “substantive experience” por “communication.” Eso es clave. Por ejemplo, yo trabajo en problemas de movilidad urbana y urbanismo. Mi intención no es reemplazar a las personas expertas en esas áreas, sino trabajar con ellas. Para ello necesito poder entablar diálogos, porque las dos áreas, a pesar de trabajar en problemas similares, tienen distintos enfoques, distintos métodos, distintas fuentes de datos, distinta terminología, y distintas prioridades. Necesito entenderlas y poder usar el mismo lenguaje que ellas. De hecho, es el/la Data Scientist quien debe adaptar su lenguaje y comunicación a las otras disciplinas. No al revés.
Reemplacemos “Code” y “Hacking Skills” por “Pensamiento Computacional”
En los dos perfiles anteriores se habla de programación. Efectivamente, es necesario programar, pero creo que el término adecuado es “Pensamiento Computacional.” Se puede ser hacker y tener habilidades de código impresionantes y aún así colapsar ante un problema de enormes dimensiones. Se puede tener habilidades de ingeniería de software y aún así no ser capaz de resolver FizzBuzz.
¿Qué es pensamiento computacional? Es la capacidad de enfrentar la resolución de problemas utilizando herramientas como diseño de algoritmos; búsqueda de patrones en los datos; separación del gran problema en problemas más pequeños, cuyas soluciones son ensambladas después; y la capacidad de abstracción, que permite extender la solución de un problema a otros.
Por supuesto, pensamiento computacional requiere programar. Pero no requiere, por ejemplo, Ingeniería de Software.
Data Scientist como Unicornios
El diagrama de Hillary Mason también dice que alguien que domina dos habilidades es nerd, y quien domina las tres es un(a) awesome nerd.
¿Sabían que a quienes dominan las tres áreas les dicen unicornios?
El motivo es simple.
No existen.
Si no existen, entonces, ¿cómo hacer Data Science?
La respuesta es: colaborando.
Eso es lo que le falta a ambas propuestas.
Para colaborar con otras personas, especialmente aquellas de otras áreas, de disciplinas distintas, de contextos aparentemente desconectados del nuestro, necesitamos ser capaces de escuchar, de adaptar nuestro lenguaje, de confiar en otras personas que puedan complementar nuestras habilidades.
Los unicornios no existen, pero a través de la colaboración podemos lograr que nuestras habilidades sumen más que todo lo que puede ofrecer un unicornio. Eso es lo que veremos en el siguiente post, que tendrá la segunda parte de la charla.
El Mejor Ejemplo (Ficticio) de Data Science que he Visto
El año pasado se estrenó la película Arrival de Denis Villeneuve. ¿La han visto? Es impresionante.
Un día aparecen varias naves espaciales esparcidas en distintos lugares del planeta. No atacan ni parecen buscar nada particular. Las agencias de inteligencia y militares de todo el mundo rodean a estas naves y entran en ellas. Se encuentran con unos seres especiales que no hablan, sino que emiten ruido.

No un ruido estructurado, sino que simplemente ruido.
En Estados Unidos, los militares acuden a una lingüista, Louise Banks, para que “traduzca” los ruidos de los extraterrestres. Ella se integra a un equipo donde hay militares, comunicadores, y un físico, Ian. Junto a Ian deben modelar el lenguaje desconocido, de modo de poder inferir qué quieren nuestros visitantes y qué están haciendo en la Tierra.

Al ver esta película pensé que representaba perfectamente un proceso de Data Science. Vemos como Louise e Ian complementan sus habilidades para descifrar la estructura y contenido de un lenguaje alienígena. Louise fue la única persona del equipo que era capaz de escuchar, y por tanto, adoptar el lenguaje de los otros. De ir más allá.

Los glifos circulares son mensajes alienígenas. ¿Qué significan? A lo largo de la película nos damos cuenta que no es tan relevante el significado como sí lo es el mecanismo de expresión y comprensión del lenguaje.
Ya habíamos mencionado que en Data Science es necesario que la investigación sea interpretable por otros. Para que sea así, no hay más alternativa que poder expresarnos en su lenguaje, y saber qué es lo que entienden y qué no. De otro modo ni siquiera entenderemos el problema.

Un Ejemplo del Mundo Real: el Instituto de Data Science
En el Instituto de Data Science de la Universidad del Desarrollo trabajamos en equipo.
, @carnby, Fernando Rojas (decano de Ingeniería UDD), Loreto Bravo (directora del IDS), Francisca Varela (gestora de transformación digital), Leo Ferres (investigador del IDS), y Pelayo Covarrubias (director de Fundación País Digital). La foto es de la premiación de Francisca, que este año ganó el premio InspiraTEC, por su trabajo en el impulso del pensamiento computacional y la programación en mujeres de todas las edades.")
Tenemos constante comunicación con empresas, con instituciones públicas, y con otras personas. Le ponemos cara a la investigación. Somos un equipo diverso en varias dimensiones, desde las habilidades mencionadas, hasta el género y la política. Esto es importante: cuando se trabaja en problemas concretos, es fácil caer en la trampa de las suposiciones. En Data Science, como en todo campo relacionado con la computación, los sesgos de género y contra minorías son comunes. Es fácil asumir que las demás personas piensan como uno, viven como uno, tienen los mismos problemas que uno, y las mismas soluciones que uno propondría serían útiles para otros(as). Pero no es así. La única manera de comprenderlo es ver las caras de los demás y ponerse en sus zapatos. Dialogar. Escuchar y observar.
Si no somos capaces de ver los sesgos en el mundo que nos rodea, ¿cómo seremos capaces de verlos en el mundo abstracto de los datos? La única manera de solucionar eso es estando en un ambiente diverso.
Continuará…
Este artículo propone mi visión personal de lo que es Data Science y sobre quien la lleva a cabo, la(él) Data Scientist. Espero que este post sea útil no solamente para quienes quieran seguir esta carrera, sino también para empresas e instituciones que están considerando incluir Data Science en su pipeline de generación de valor.
En la segunda parte de este post mostraré cómo desarrollar las habilidades que tiene un(a) Data Scientist. Aunque existen muchas maneras de realizar estudios formales, como Diplomados, Másters y Doctorados, éstos no aseguran que uno desarrolle el conjunto de habilidades. Sí pueden ayudar a dar un buena base sólida para comenzar, pero no es el único camino. El siguiente artículo expondrá una manera de desarrollarlas haciendo.
Nos vemos pronto ;)
Última actualización: